
Les modèles mathématiques de maladies infectieuses, d'abord outils purement théoriques, ont commencé à être mis en pratique avec le problème du SIDA dans les années 1980. Lors de la pandémie Covid 19, les modélisations mathématiques ont connu un essor lors de la prise de décision relatives aux politiques de santé publique et a également contribué à l'épidémiosurveillance de la maladie.
Bien avant cela, depuis la pandémie de grippe espagnole, des modèles compartimentaux sont utilisés pour faciliter les calculs de probabilité de contagion. Ces modèles divisent la population en classes épidémiologiques.
Histoire
Le cours d'une épidémie dans une population dépend de paramètres complexes et très nombreux (stades cliniques possibles, déplacement des individus, souches de la maladie).
Les modèles mathématiques se sont peu à peu affirmés comme outils d'aide à la décision pour les politiques publiques car permettant de prévoir les conséquences sanitaires d'actions aussi variées que la vaccination, la mise en quarantaine ou la distribution de tests de dépistage.
Une approche fondatrice fut celle des modèles compartimentaux créés en 1927 par Anderson Gray McKendrick et William Ogilvy Kermack ; elle fut ensuite étendue par ces derniers dans deux autres articles scientifiques quelques années plus tard (1932 et 1933). Le principe est de diviser la population en classes épidémiologiques telles que les individus susceptibles d'être infectés, ceux qui sont infectieux, et ceux qui ont acquis une immunité à la suite de la guérison. Depuis, cette approche est utilisée pour modéliser de nombreuses maladies, et continue d'être un sujet de recherche actif en prenant en compte de nouveaux éléments tels que les découvertes de la science des réseaux.
Principes fondamentaux
Compartiments et règles

Un modèle épidémiologique se fonde sur deux concepts : les compartiments et les règles. Les compartiments divisent la population en divers états possibles par rapport à la maladie. Par exemple, William Ogilvy Kermack et Anderson Gray McKendrick proposèrent un modèle fondateur dans lequel la population était divisée entre les individus susceptibles de contracter la maladie (compartiment ), et les individus infectieux (compartiment ). Les règles spécifient la proportion des individus passant d'un compartiment à un autre. Ainsi, dans un cas à deux compartiments, il existe une proportion d'individus sains devenant infectés et, selon les maladies, il peut aussi exister une proportion d'individus infectieux étant guéris. L'acronyme utilisé pour un modèle est généralement fondé sur l'ordre de ses règles. Dans le modèle , un individu est initialement sain (), peut devenir infecté () puis être guéri () ; si la guérison n'était pas possible, alors il s'agirait d'un modèle .








Sept compartiments sont couramment utilisés : , , , , , et . Le compartiment est nécessaire, puisqu'il doit initialement exister des individus n'ayant pas encore été infectés. Lorsqu'un individu du compartiment est exposé à la maladie, il ne devient pas nécessairement capable de la transmettre immédiatement, selon l'échelle de temps considérée dans le modèle. Par exemple, si la maladie nécessite deux semaines pour rendre l'individu infectieux (ce qui est appelé une période de latence de deux semaines) et que le modèle représente l'évolution journalière de la population, alors l'individu ne va pas directement dans le compartiment (infectieux) mais doit passer par un compartiment intermédiaire. Un tel compartiment est noté , pour les individus exposés.




Selon les maladies, il peut être utile de distinguer les individus infectés. Si la maladie est causée par des organismes parasites tel le ver parasite ou les tiques, alors la concentration de ces organismes peut justifier de diviser la classe en plusieurs classes représentant plusieurs niveaux de concentration. Lorsque la maladie est causée par des virus ou des bactéries, un grand nombre de modèles ne divisent pas la classe : ils considèrent que l'individu est infecté ou ne l'est pas. Cependant, dans le cas d'un virus, il existe un analogue à la concentration en organismes parasitaires : il s'agit de la charge virale, qui exprime la concentration du virus dans un volume donné tel que le sang. Les individus peuvent donc être distingués selon leur charge, puisque celle-ci les rend infectieux à des niveaux différents, ainsi qu'illustré ci-contre dans le cas du VIH.
Après qu'un individu a été infecté, trois cas de figure peuvent se produire. Premièrement, l'individu peut décéder, auquel cas il relève du compartiment . Deuxièmement, la maladie peut se terminer d'elle-même et conférer à l'individu une immunisation contre la réinfection, et il est assigné à un compartiment . Enfin, l'individu peut toujours être infectieux mais il se retrouve isolé de la population par politique de quarantaine, correspond à un compartiment . Séparer les individus morts des individus en quarantaine permet également de tenir compte du fait que ces derniers peuvent éventuellement guérir et réintégrer le compartiment . Outre les compartiments cités, représente les individus disposant d'une immunité à la naissance (par voie maternelle), et représente les individus porteurs de la maladie (carriers) mais qui n'en expriment pas les symptômes.

Représentation mathématique à l'aide d'équations différentielles

Les modèles compartimentaux permettent d'estimer comment le nombre d'individus dans chaque compartiment varie au cours du temps. Par abus de notation, la lettre utilisée pour représenter un compartiment est également employée pour représenter le nombre d'individus dans le compartiment. Par exemple, S est utilisé dans une équation pour représenter le nombre d'individus sains. Une formulation plus rigoureuse, et parfois employée, consiste à utiliser S(t) à la place de S, ce qui explicite qu'il s'agit d'une fonction et que le nombre dépend du temps . Pour savoir comment le nombre d'individus dans un compartiment varie au cours du temps, il est nécessaire de savoir comment déduire le nombre d'individus d'une étape à une autre, c'est-à-dire du temps au temps . Cette différence dans le nombre d'individus est donnée par la dérivée. Ainsi, correspond à la balance du nombre d'individus par rapport au compartiment S. Une balance négative signifie que des individus sortent, tandis qu'une balance positive signifie que des individus entrent. La balance porte le nom d’incidence car elle représente le nombre d'infections de la maladie.





Dans le cas d'un modèle SIR, un individu commence sain, peut devenir infecté puis se remettre de sa maladie avec une immunisation. Si le paramètre de transmission est noté p, alors

où est appelée la force d'infection. Cela exprime que l'effectif d'individus sains diminue à proportion du nombre d’individus déjà infectés et du nombre d'individus encore non-infectés. L'équation mettant en relation la fonction S et sa dérivée, il s'agit d'une équation différentielle, d'ailleurs absolument semblable à la cinétique d'une réaction chimique élémentaire bimoléculaire. Dans les modèles simples, ces équations sont des équations différentielles ordinaires (EDO, ou ODE en anglais). Si la proportion d'individus infectieux retirés de la population est , alors , ce qui signifie que le nombre d'individus infectieux augmente avec ceux nouvellement infectés et diminue avec ceux retirés. Enfin, tous les individus guéris sont d'anciens individus infectieux, d'où . En additionnant les trois équations différentielles, il apparaît que , ce qui signifie que le nombre d'individus dans la population est toujours le même. Ce modèle considère donc une population stable (ou close), c'est-à-dire dans laquelle il n'y a ni naissance, ni émigration ou immigration. L'hypothèse d'une population stable est justifiée lorsque l'épidémie se déroule sur une petite échelle de temps, et si ce n'est pas le cas alors il peut devenir important de considérer les effets démographiques. Dans le cadre d'un modèle avec un état intermédiaire comme SEIR, les équations pour dS/dt et dR/dt sont les mêmes. En dénotant par le taux d'individus exposés qui deviennent infectieux, alors , et .








L'épidémie de peste bubonique à Eyam, en Angleterre, entre 1665 et 1666, constitue un exemple célèbre illustrant la dynamique d'un modèle SIR dans un cas réel. Pour lutter contre la peste, le prêtre William Mompesson propose des mesures de quarantaine qui sont suivies par toute la population, afin d'empêcher que la maladie ne se diffuse à d'autres communautés. Ceci s'avère être une erreur. En effet, cette maladie est principalement transmise par les puces de rat. Or la quarantaine maintient la promiscuité entre puces, rats et hommes, et augmente drastiquement le taux d'infection ; de plus, le confinement n'empêche pas les rats de sortir et de contaminer d'autres communautés. Malgré ou à cause du confinement, 76 % des habitants décèdent.
Dans cet exemple, la quantité d'individus sains (S) et infectés (I) est connue à plusieurs dates, et la quantité d'individus disparus (R) est déduite de la taille de la population de départ. En utilisant ces données, le modèle SIR donne : et . Brauer conclut : « Le message que cela suggère aux mathématiciens est que les stratégies de contrôle fondées sur des modèles erronés peuvent être dangereuses, et qu'il est essentiel de distinguer entre les hypothèses qui simplifient mais ne changent pas substantiellement les effets prédits, et les hypothèses erronées qui font une différence importante ».


Nombre de reproduction de base (R0)
Pour toute maladie, un enjeu sanitaire majeur est de savoir si elle se propage dans la population et à quelle vitesse (temps de doublement). Ceci revient à calculer le nombre moyen d'individus qu'une personne infectieuse infecte tant qu'elle est contagieuse. Ce taux est appelé le nombre de reproduction de base, et est noté R0 (ratio).
Ce taux est intuitivement facile à comprendre, mais s'il est lié au pathogène, son calcul s'avère complexe. Le R0 doit être utilisé avec prudence, car il peut conduire à des erreurs d'interprétation, tant sur le rôle réel que ce R0 a sur la propagation d'une maladie infectieuse qu'aux capacités de contrôle d'une épidémie.
Le calcul du R0 présuppose une population où tous les individus sont sains, sauf l'individu infectieux introduit (le patient zéro). Si , alors l'individu infecté contamine moins d'un autre individu en moyenne, ce qui signifie que la maladie disparaît de la population. Si , alors la maladie se propage dans la population et devient épidémique. Déterminer R0 en fonction des paramètres du modèle permet ainsi de calculer les conditions dans lesquelles la maladie se propage.


Comme le notent van den Driessche et Watmough, « dans le cas d'un seul compartiment infecté, est simplement le produit du taux d'infection et de sa durée moyenne ». Lorsque le modèle est simple, il est souvent possible de trouver une expression exacte de R0. Pour cela, on considère généralement que la population est à l'état d'équilibre ; autrement dit, que le nombre d'individus dans chaque compartiment ne varie plus. Dans le cas du modèle SI, cela revient à poser les conditions et . Pour résoudre un tel système d'équations différentielles, c'est-à-dire pour trouver les points d'équilibre, une possibilité est d'utiliser l'analyse qualitative. Selon Kermack & McKendrick , étant la probabilité de transmission, c le nombre de contacts par unité de t et d la durée de la période contagieuse, d'où le temps de doublement .






S'il existe plusieurs compartiments représentant des individus infectieux, d'autres méthodes sont nécessaires, telle la méthode next-generation matrix (« matrice de la génération suivante ») introduite par Diekmann. Dans l'approche de van den Driessche et Watmough pour cette méthode, la population est divisée en n compartiments dont les m premiers représentent les individus infectés. Autrement dit, au lieu de s'intéresser à un seul compartiment d'individus infectés comme précédemment, la méthode considère que les individus infectés sont distribués sur m compartiments. Le but est donc de voir s'établir les taux d'évolution de la population dans chacun de ces compartiments.

Pour cela, deux aspects interviennent. Premièrement, des individus peuvent avoir été nouvellement infectés, et proviennent ainsi de compartiments autre que les m premiers. Deuxièmement, les individus infectés peuvent se déplacer entre les compartiments infectés.
Formellement, le taux d'individus nouvellement infectés rejoignant le compartiment i est noté . La différence entre les taux d'individus sortant et entrant dans le compartiment i par d'autres moyens que l'infection est notée . Déterminer l'évolution d'un compartiment dépend de tous les autres compartiments, ce qui conduit à l'expression du système par deux matrices carrées F et V de taille , définies par :






La matrice de génération suivante est . Une propriété de cette matrice est que si sa plus grande valeur-propre est supérieure à 1, alors les générations grandissent en taille ; à l'opposé, si la plus grande valeur propre est inférieure à 1, alors les générations diminuent. La plus grande valeur propre correspond donc au nombre de reproduction de base. La plus grande valeur propre d'une matrice A est connue comme son rayon spectral et noté . Ainsi, .



L'approche matricielle pour calculer le nombre de reproduction de base dans des modèles complexes montre le lien qui existe entre les modèles compartimentaux et les modèles matriciels de population.
Selon le théorème du seuil, si > 1, il faut prévoir une extension de la maladie ; si < 1, on peut prévoir une extinction de la maladie.
Le taux R0 est important pour déterminer le risque qu'un nouveau pathogène cause une épidémie (impossible si <1, possible si >1) et pour estimer la taille finale de l'épidémie, avec ou sans mesures de contrôle.
Nota : Rétrospectivement on calcule aussi le (nombre de reproduction à l'instant t, ou instantaneous reproduction number pour les anglophones).

Limites à l'utilisation du R0
Le R0 est nécessairement basé sur des simplifications et il dépend de très nombreux facteurs, en partie imprédictibles (ex : conjonction d'un tremblement de terre, d'un évènement météorologique, socioéconomique ou d'une crise politique ou d'une guerre dans un contexte d'épidémie).
Le choix des modèles (et des paramètres qu'on y entre) influe sur les résultats. Ainsi, en un mois (entre le et le ), 12 équipes scientifiques ont cherché à calculer le R0 de la maladie Covid-19, en utilisant différents modèles et données. Leurs résultats s'étalaient entre 1,5 et 6,68 .
Selon Bauch & al. (2020) un tel manque de concordance est normal et peut avoir 3 raisons :
- Les variables considérées diffèrent ;
- Les méthodes de modélisation diffèrent ;
- Les procédures d’estimation diffèrent.
Dans le cas du Covid-19, Liu & al. (2020) notent que les études utilisant des méthodes déterministes ont produit des estimations plus élevées que celles utilisant des modèles stochastiques et statistiques.
Estimer ce R0 suppose que le nombre d'infections secondaires produites par un seul cas ne varie pas . En réalité, le virus peut muter et devenir plus ou moins contagieux ou infectieux au cours de sa propagation. On sait également qu'il existe des individus superinfecteurs; ainsi, pour la CoVid-19, une seule personne venant d'une conférence à Singapour via le Royaume-Uni aurait transmis l'infection à onze personnes pendant ses vacances en France. Enfin, des événements de super-infection jouent une grande importance quand un seul sujet, éventuellement asymptomatique, infecte de nombreuses autres personnes lors de fêtes, de mariage, de cérémonie religieuse (comme on l'a vu avec les maladies SRAS et MERS et Covid19).
Aucun modèle ne peut prendre en compte toute l'hétérogénéité spatiotemporelle d'un contexte écoépidémiologique, ni même le degré de transmissibilité ou la vulnérabilité à une infection. En outre, dans le monde réel, le nombre reproductif de base (R0) est constamment modifié au cours de l'épidémie, notamment par les mesures barrières et les mesures de contrôle adoptées ou imposées pour justement réduire le R0, en agissant sur :
- La durée de la contagiosité ;
- La probabilité d'infection par contact ;
- Le taux de contact.
Ainsi la quarantaine peut se montrer remarquablement efficace, surtout dans le cadre d'efforts mondiaux bien coordonnés, pour freiner la propagation de la maladie puis éviter sa réapparition[réf. nécessaire].
Le nombre reproductif de contrôle (Rc) désigne la valeur de R en présence de mesures de contrôle ; si Rc est maintenu à des valeurs inférieures à un, alors la maladie est finalement éradiquée.
Viceconte & Petrosillo (2020) rappellent qu'une tendance épidémique (ou notre capacité à la contrôler) ne repose pas uniquement sur R0. Parmi les autres variables à prendre en compte figurent : le nombre de cas initiaux ; le délai entre l'apparition des symptômes et l'isolement ; le traçage rapide des contacts probables ; le taux de transmissions survenues avant l'apparition des symptômes et la part des infections subcliniques (asymptomatiques).
Le nombre de reproduction effectif (Re) est le nombre de reproduction tenant compte des personnes déjà immunisées.
Extensions
Hétérogénéité des populations réelles

Dans les modèles compartimentaux, la seule particularité d'un individu est la classe épidémiologique à laquelle il appartient. Ceci permet de distinguer les individus en établissant des classes pour différents comportements : par exemple, dans des maladies sexuelles telles que le SIDA, il peut exister une classe pour les individus ayant un comportement à risque élevé (forte fréquence de rapports sexuels, rapports non protégés...) et une autre pour les individus ayant un comportement moins risqué. En créant de telles classes, les individus peuvent avoir des attributs prenant un petit nombre de valeurs : le comportement est ainsi un attribut, et risque élevé ou risque normal constituent ses deux valeurs. La population dans les modèles compartimentaux est ainsi hétérogène, c'est-à-dire que tous les individus ne sont pas absolument identiques. Autrement dit, les individus ne sont identiques que pour les attributs n'étant pas explicitement représentés dans une classe.
Les recherches du début des années 2000 à 2010 ont mis en avant le fait que les individus étaient très différents dans leur nombre de contacts. Certains individus peuvent ainsi avoir une poignée d'amis, ce qui limite leur exposition à des maladies infectieuses, tandis que d'autres peuvent être extrêmement sociaux, ce qui augmente la probabilité qu'ils soient infectés. Deux exemples de ces différences entre individus sont données par Bansal, Grenfell et Meyers. Premièrement, en 2003, deux voyageurs développèrent un syndrome respiratoire aigu sévère, et l'un engendra 200 cas à Toronto tandis qu'aucun ne fut reporté pour l'autre à Vancouver. Deuxièmement, 60 % des infections lors de l'épidémie de gonorrhée de 1984 aux États-Unis provenaient de 2 % de la population. Bien qu'il soit possible de prendre en compte le nombre de contacts des individus en utilisant des classes, cette approche est inadaptée. En effet, les classes ne permettent pas d'analyser la structure de la population et ses conséquences pour les maladies : il est possible de dire qu'un individu a plus de contacts qu'un autre, mais il est par exemple impossible de déterminer quels individus vacciner en priorité selon le rôle qu'ils jouent dans la population. Dans un cas simplifié, la population pourrait être constituée de deux communautés ne se côtoyant que par le biais d'un individu, et vacciner cet individu empêcherait la maladie de se répandre d'une communauté à l'autre.
Prendre en compte le fait que les individus ont différents nombres de contact peut être réalisé sans avoir besoin de représenter explicitement les contacts par un graphe tel qu'illustré ci-contre. Parmi les approches, celle de Pastor-Satorras and Vespignani est une des plus citées et consiste à modifier les équations différentielles pour y inclure les différences en nombre de contacts. Les auteurs s'intéressent à un modèle SIS, c'est-à-dire que les individus sont susceptibles, peuvent devenir infectés et redeviennent susceptibles lors de la guérison ; il n'y a donc pas de décès ou d'immunité acquise. La proportion d'individus infectés au temps est notée , le taux d'infection est noté , et le nombre moyen de contacts par personne est noté . Pour simplifier le modèle, la quantité d'individus guéris n'est pas spécifiée par un taux : l'unité de temps est considérée comme étant choisie assez longue pour que tous les individus soient guéris d'une étape à une autre. Ainsi, si tous les individus avaient le même nombre de contacts, alors l'évolution de la proportion d'individus infectés serait donnée par la dérivée :




La partie résulte de la rémission de tous les individus infectés. La seconde moitié se comprend de la façon suivante : chacun des individus a contacts, chacun de ces contacts est un individu sain avec probabilité , et l'infection d'un individu sain en contact est faite avec un taux . Dans le cas où les individus n'ont pas tous le même nombre de contacts, l'équation s'intéressera alors au taux d'individus infectés ayant contacts, ce qui est noté .




La méthode de Pastor-Satorras et Vespignani est particulièrement connue en raison de son résultat : le calcul du nombre de reproduction de base donne lorsque , où et sont deux constantes. De façon simplifié, ce résultat établit que dans une population où la majorité des individus a peu de contacts et quelques-uns en ont beaucoup, ce qui est souvent le cas, alors il n'existe pas de seuil à la propagation de la maladie : il est impossible d'empêcher la maladie de se propager. Cependant, le résultat a été excessivement repris dans cette forme simplifiée sans tenir compte des hypothèses sur lesquels il repose. En effet, Pastor-Satorras et Vespignani considèrent que seule la propriété est en place et qu'en tous autres aspects la population est aléatoire ; de plus, l'exposant est choisi et la population est considérée de taille infinie. Des études récentes ont montré que toutes les hypothèses doivent être simultanément vérifiées pour parvenir au résultat. Par exemple, il suffit de considérer un modèle compartimental autre que SIS ou une population avec davantage de propriétés pour trouver de nouveau des conditions dans lesquelles la maladie ne peut plus se propager.




Déplacements

La population réelle est répartie dans plusieurs villes. À l'intérieur d'une ville, les individus peuvent se contaminer. Un individu contaminé peut se déplacer dans une autre ville et y propager la maladie, et d'une façon similaire un individu sain peut se déplacer dans une ville où il sera infecté et ramener la maladie dans sa ville d'origine. Modéliser ces aspects permet de prendre en compte l'évolution de la maladie dans un espace. Le modèle de Bartlett est cité par Arino comme le premier à avoir pris en compte l'aspect spatial. Les individus sont dans deux états possibles, et . Deux endroits sont définis : les individus se trouvant au premier peuvent être dans les états et , tandis que les individus se trouvant au second peuvent être dans les états ou . Afin d'autoriser les déplacements de population, il est possible pour un individu de changer d'état entre et d'une part, et entre et d'autre part. Le modèle de Bartlett ne se limite pas au strict déplacement d'individus entre les deux endroits puisqu'il considère que les individus dans deux villes interagissent : par exemple, la proportion d'individus de devenant infectée n'est pas simplement mais , ce qui représente l'hypothèse que tous les individus dans sont en contact avec un même nombre d'individus dans et .






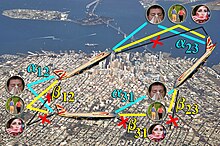
Le modèle de Grais, Ellis et Glass s'intéresse à la diffusion de la grippe lorsque les individus voyagent par avion entre des villes. Les auteurs considèrent les individus d'une ville comme pouvant être susceptibles, dans la période d'incubation (c'est-à-dire qu'ils ont été infectés mais ne le savent pas encore car la maladie ne s'est pas déclarée) ou infectieux. L'hypothèse est que les individus, ou les compagnies aériennes, appliquent un principe de précaution : les individus infectieux ne voyagent pas, tandis que les autres y sont autorisés. Ainsi, comme dans la réalité, la maladie peut être véhiculée par des individus en période d'incubation. Afin d'être réaliste, le modèle calcule le nombre d'individus prenant des vols à partir du nombre d'habitants dans des grandes villes mondiales. La zone des villes et le mois sont également utilisés pour prendre en compte les variations saisonnières de la grippe. En considérant un ensemble de villes entre lesquelles les individus dans certains états peuvent se déplacer, ce modèle montre la nécessité d'une modélisation sous forme de multi-graphe. Concrètement, un multi-graphe décrit les lieux par des sommets, et deux lieux peuvent être reliés par autant d'arcs qu'il y a d'états permettant de s'y rendre. Par exemple, si les individus sains et en période d'incubation peuvent se rendre de Paris à Manille, alors Paris et Manille sont représentés par deux sommets, et il existe deux arcs allant de Paris à Manille : le premier représente le flot de passagers sains, et le second le flot de passagers en période d'incubation.

Les travaux de Fromont, Pontier et Langlais cités par Arino s'intéressent à une maladie se transmettant entre les chats : ainsi qu'ils le notent, « les structures sociales et spatiales des chats changent selon la densité », qui va de 1 jusqu'à 2000 chats par km². Les auteurs considèrent les chats dans deux types de lieux : les « fermes » et les « villages ». Dans les fermes, il y a peu de chats et tous se rencontrent donc, tandis que dans un village le nombre de chats est trop élevé pour qu'ils soient tous en contact. Ainsi, la maladie fonctionne différemment selon le lieu considéré, ce qui est rarement appliqué à des modèles avec déplacement. Arino suggère que conjuguer le déplacement avec l'hétérogénéité de la population constitue une piste pour des recherches futures.
Prise en compte de l'âge


L'âge peut être un facteur important de la diffusion d'une maladie pour deux raisons. Premièrement, la résistance des sujets peut dépendre de l'âge. Un exemple extrême consiste à séparer les enfants des adultes : dans le cas de d'épidémies de rougeole aux États-Unis en 1827 et 1828, la population étudiée était composée à 21 % d'enfants mais ceux-ci représentaient 44 % des décès. Deuxièmement, le comportement des sujets change avec l'âge : ainsi, il est considéré que la probabilité qu'un individu s'engage dans une activité sexuelle à risque décroît avec l'âge, et des modèles prennent en compte l'impact de l'âge sur des aspects tels que le taux de changements de partenaires sexuels. La prise en compte de l'âge se fait en utilisant une nouvelle variable . Ainsi, dans le modèle SIR, les quantités d'individus infectés au temps ne sont plus seulement notées , et , mais , et pour représenter la quantité avec un âge donné. Au temps , individus avec l'âge deviennent infectés. Si ces individus ont des contacts uniquement avec des individus du même âge , alors la force de l'infection ne dépend que du nombre de personnes infectées d'âge et du taux d'infection pour cet âge :








En revanche, si un individu a des contacts avec des individus de tout âge, alors il faut prendre en compte le taux avec lequel des individus sains d'âge sont en contact avec des individus infectés d'âge . Ainsi, la force avec laquelle les individus d'âge seront infectés consiste à considérer le nombre de personnes pour chaque âge possible et le taux d'infection associé à cet âge. La population étant considérée comme continue par rapport à l'âge, cette approche s'exprime par :



Dans la version du modèle SIR sans prise en compte de l'âge, l'évolution du nombre d'individus infectés était donnée par . Dans le cas avec âge, est fonction de et . Dans son expression ci-dessus, dépend de l'intégrale de . Ainsi, le changement du nombre d'individus infectieux, c'est-à-dire la dérivée de , dépend de l'intégrale de pour la partie pS(t)I(t), et de (pour la partie . L'équation devient donc intégro-différentielle, puisqu'elle fait intervenir à la fois l'intégrale et la dérivée de la fonction.





Parmi les modèles compartimentaux avec prise en compte de l'âge, Sido Mylius et ses collègues de l'Institut national de la santé publique et de l'environnement (RIVM, Pays-Bas) se sont intéressés à un modèle SEIR pour la grippe. La distribution des âges dans leur modèle provient des statistiques des Pays-Bas, et la transmission entre individus de deux groupes d'âge provient de l'étude sur la transmission des maladies respiratoires infectieuses de Wallinga, Teunis et Kretzschmar, elle-même fondée sur la fréquence des contacts entre individus de deux classes d'âge à Utrecht en 1986. La fréquence de contacts entre individus de deux classes d'âges est traditionnellement exprimée par la matrice WAIFW (who acquires infection from whom, soit « qui acquiert une infection de qui »). Cette matrice est nécessairement non-symétrique : par exemple, tout enfant a un parent (c'est-à-dire adulte) avec qui il est en contact, mais tout adulte n'a pas nécessairement un enfant, et ainsi la fréquence des contacts d'un enfant vers un adulte est en moyenne plus élevée que d'un adulte vers un enfant. Dans le modèle de Mylius, les individus pour chaque état sont divisés par âge, puis par groupe de risque. Le nombre de nouvelles infections pour des individus sains d'âge et groupe est calculé en considérant le nombre d'individus sains , la fréquence de leurs contacts avec des individus d'âge (considérée comme dépendant seulement de l'âge), le nombre d'individus infectieux avec lesquels ils peuvent être en contact, et la probabilité de transmettre la maladie lors d'un contact. Dans ce modèle, la population est considérée comme discrète, et l'évolution du nombre d'individus sains fait ainsi intervenir une somme plutôt qu'une intégrale :







Population proactive : agir face à la maladie

Comme « beaucoup de modèles de transmission des maladies », les modèles exposés dans les sections précédentes « considèrent une population passive qui ne répondra pas (changera son comportement) face à la diffusion d'une maladie infectieuse ». Cependant, il existe des campagnes pour sensibiliser la population, comme la Journée mondiale de lutte contre le SIDA, ou pour inciter à la vaccination. Des campagnes de masse peuvent déboucher sur des résultats très faibles, tels que la prise d'un test par moins de 1 % du public concerné. Ainsi, l'étude de la façon dont la population réagit face à l'information fait partie de certains modèles épidémiologiques.
Il suffit qu'une proportion donnée de la population acquière une immunité protectrice, par une infection ou par vaccination, pour qu'elle serve de tampon au reste de la population. Ce principe, appelé immunité grégaire, repose sur le fait qu'en diminuant le nombre d'individus infectés et infectieux, on diminue significativement la probabilité qu'un individu sensible soit infecté.
Si p est la proportion de la population qu'il faut immuniser pour bloquer le déclenchement d’une épidémie . Ainsi, pour la grippe p = 50-75 %, pour la rougeole p = 93-95 %.

Selon Kermack & McKendrick , étant la probabilité de transmission, c le nombre de contacts par unité de t et d la durée de la période contagieuse. Les autorités peuvent ainsi agir sur par ses trois composantes : diminution de la probabilité de transmission par des mesures d'hygiène et de prophylaxie (utilisation d'antiviraux curatifs et préventifs, vaccins, lavage des mains, masques de protection) ; diminution du taux de contacts par des incitations à diminuer la vie sociale (augmentation de la « distance sociale » par fermeture des crèches, des écoles, l'isolement des malades, la suppression des rassemblements publics, la réduction des mouvements de population, etc.) ; diminution de la durée de contagiosité (utilisation d'antiviraux, de médicaments à visée symptomatique).
Annexes
Articles connexes
Références
|
|
Bibliographie
- (en) Anderson R. M., May R. M., « Infectious Diseases of Humans », Oxford University Press, 1991.
- (en) Diekmann O., Heesterbeek J. A. P., « Mathematical Epidemiology of Infectious Diseases: Model Building, Analysis and Interpretation », Wiley, 2000.
- (en) Brauer F., Castillo-Chavez C., « Mathematical Models in Population Biology and Epidemiology », Springer, 2001.
- (en) Britton N. F., « Essential mathematical biology », Springer undergraduate mathematics series, Springer, 2003.
- (en) Thieme H. R., « Mathematics in Population Biology », Princeton Series in Theoretical and Computation Biology, Princeton University Press, 2003.
- (en) Krämer A., Kretzschmar M., Krickeberg K., « Modern Infectious Disease Epidemiology: Concepts, Methods, Mathematical Models, and Public Health », Springer, 2010.
- Bacaër N., « Mathématiques et épidémies », Cassini, 2021.
- Ramsès Djidjou-Demasse, Christian Selinger et Mircea T. Sofonea, « Épidémiologie mathématique et modélisation de la pandémie de Covid-19 : enjeux et diversité », Revue Francophone des Laboratoires, vol. 2020, no 526, , p. 63–69 (DOI 10.1016/S1773-035X(20)30315-4, lire en ligne)
Lectures complémentaires
- Sur le nombre de reproduction de base (1.3)
- (en) Allen L.J.S., van den Driessche P., « The basic reproduction number in some discrete time epidemic models », Journal of Difference Equations and Applications, volume 14, numéro 10, pp. 1127 – 1147, 2008.
- Sur la modélisation du comportement dans la transmission des maladies (2.1)
- (en) Gonçalves S., Kuperman M., « The social behavior and the evolution of sexually transmitted diseases », Physica A: Statistical Mechanics and its Applications, volume 328, p. 225-232, 2003.
- Sur l'impact des liens entre individus (2.1)
- (en) Kostova, T., « Interplay of node connectivity and epidemic rates in the dynamics of epidemic networks », Journal of Difference Equations and Applications, volume 15, numéro 4, pp. 415 – 428, 2009.
- (en) Kooij R. E., Schumm P., Scoglio C., Youssef M., « A new metric for robustness with respect to virus spread », Proceedings of the 8th International IFIP-TC 6 Networking Conference, pp. 562 – 572, 2009.
- (en) Ayalvadi G., Borgs C., Chayes J., Saberi A., « How to Distribute Antidotes to Control Epidemics », Random Structures and Algorithms, 2010.
- Sur le déplacement des individus (2.2)
- (en) Brockmann D., « Human Mobility and Spatial Disease Dynamics », Reviews of Nonlinear Dynamics and Complexity, Schuster H. G. éditeur, Wiley-VCH, 2009.
- Sur la matrice WAIFW des contacts entre groupes d'âges (2.3)
- (en) Van Effelterre T., Shkedy Z., Aerts M., Molenberghs G., Van Damme P., Beutels P., « Contact patterns and their implied basic reproductive numbers : an illustration for varicella-zoster virus », Epidemiology and infection, volume 137, numéro 1, pp. 48–57, 2009.